A Brief Introduction To Sentence Embedding Models
Generally, text embedding models take a sequence of words as an input, and encode the semantic meaning into a numerical vector of some dimension. In principle each word (really, the word is a sub-word and is called a token but don't worry about that for now) is assigned its own vector. For the purposes of this introduction, think of each word in the sequence of words as a vector in some high-dimensional space.
Models can go a step further, and combine each word's personal vector to create a single vector, describing the entire sentence. These are sentence embedding models.
Many AI companies offer sentence embedding models, just like they do Large Language Models. For example, OpenAI offer the text-embedding-3-small and text-embedding-3-large models, which have vector dimensions of 1536 and 3072 respectively. It is worth noting these models are constantly changing, and so they might not have the exact same architecture described in the following introduction.
Sentence embedding models most commonly use a transformer based architecture. This post does not go into detail of the transformer architecture, but I want to introduce a core mechanism of it: Attention.
Attention is the process of allowing sequence items (e.g. a word in a sequence of text) to read and write information from other sequence items. In principle, attention can be used for any sequential problem, not just text. As an example, the attention mechanism allows a model to understand that the word "red" in the following sentence is used to describe the colour of the "car":"The red car drove down the road". In this sense, we might expect the car vector understanding of the car has been enriched by attention, as it now has an understanding that the car is red.
We can split attention into bidirectional and causal attention. Where bidirectional means each sequence element can read and write information from every other sequence item. In causal attention, sequence items can only read information from previous items.
The first stage of training a sentence embedding model is to first train a text embedding model (e.g. the BERT model). This part uses masked language modelling - the model outputs a vector for each token, during training random tokens are masked (the model isn't told what they are), and the model is trained to recover them by projecting the predicted token over the vocabularly and using a cross-entropy loss or something similar. This forces the model to learn contextual relationships between words in a sentence.
As a very naive example we might expect a training example to be something like:
"The ___ sat on the mat."
The model will perform bidirectional attention on each token, and produce a vector for the token "___" which, when multiplied by the big matrix, gives us a probability distribution over our vocabulary. In this example we might hope the output distribution is peaked around cute little animals.
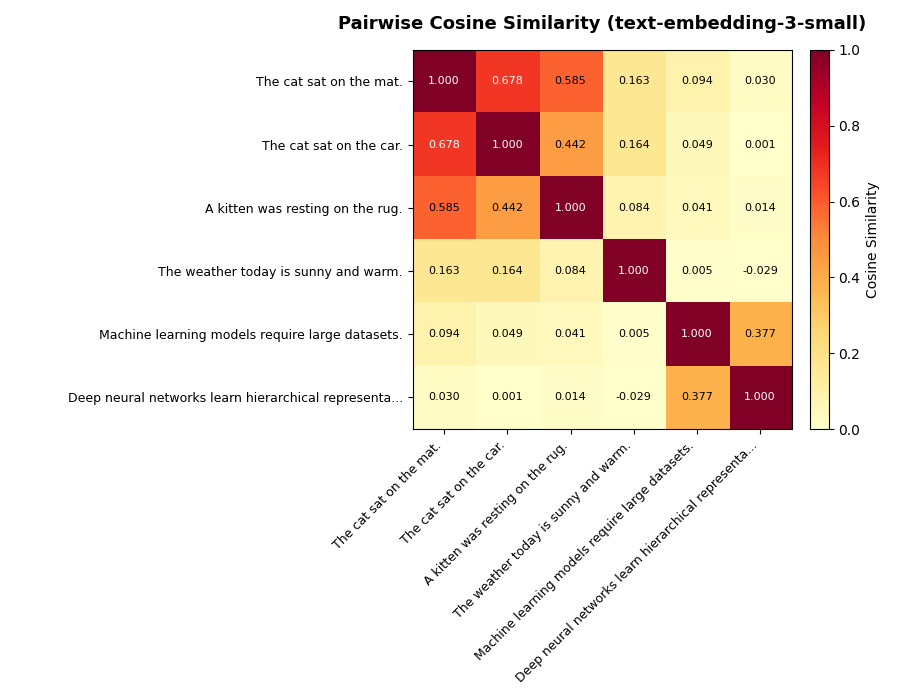
Sentence embedding models take a pretrained BERT model, pool the token vectors into a single sequence vector (pooling combines the per-token vectors into a single vector — most commonly by averaging them), and then fine-tune using contrastive learning to get a sentence embedding model (e.g. the Sentence-BERT model). Contrastive learning trains the model using pairs of similar and dissimilar sentences, pushing their vectors closer together or further apart respectively (using some metric like cosine similarity). The figure below shows the cosine similarity between a set of example sentences. Cosine similarities closer to 1 suggest more similar semantics, whilst smaller similarities are less similar. In principle cosine similarity is in the range [-1, 1], so sentences of opposite semantic meaning would likely have negative similarity.
This is the end of the introduction of sentence embedding models. I do introduce some additional concepts below but it is not really in scope.
← Back to ArticleIn principle there are two main flavours of transformer architecture, the Encoder and Decoder. Sentence embedding models work using the encoder flavour. Language models you might be familiar with (e.g. Chat-GPT) use the decoder flavour. For completeness I introduce the decoder flavour next.
The decoder works by again computing
attention
really this is called self-attention but I don't think the distinction is particularly useful here
on all sequence items, but this time tokens can only attend to tokens earlier on in the sequence, this is causal attention. The model outputs a vector that when multiplied by a
"big vocabulary"
Dwight: No I disagree. "R" is among the most menacing of sounds. That's why they call it "m*rder." And not "muck-duck."
Michael: Okay too many different words coming at me from too many different sentences.
Dwight: Lock your door!
The Office - Mafia • Season 6, Episode 6
matrix, produces a probability distribution (called logits) over the predicted next word. By vocabulary, we mean a literal matrix containing every word the model can parse (GPT-3 has a vocabulary of around 50,000 tokens).
At first these seem similar — both produce vectors — but the key difference is what those vectors represent. In the encoder case, we want a semantically rich representation of the whole input. In the decoder case, we want the vector to enable us to predict the next token.
Decoder models are trained most commonly with some variation of cross-entropy loss (similar to encoder-based transformers!), how close is the output logit distribution to choosing the correct next word.
Continuing on our naive examples, we might expect a training example to be like:
"The cat sat on the ___"
The model needs to learn to produce a vector that, when multiplied by a big matrix, produces a logit distribution peaked on words like "mat". But, recall that with causal attention, tokens can only attend to previous tokens — so "on" can see "cat", but "cat" cannot see "on".
There are lots more processes I do not talk about related to the transformer architecture: Softmax, Layer norm, Query, Key and Value matrices, MLP layers, etc. But for this post, I wanted to introduce sentence embedding models briefly and readers can explore the details if interested.