Who's that Pokémon?
Introduction
I wanted to get some hands-on experience with Vision Language Models -- models that can process both images and text. Specifically, I was curious about what happens inside the model when it looks at an image. Can we pull out the model's internal representation of what it sees, and is that representation meaningful? I picked Pokémon as the subject for a few reasons. There are a lot of them, they're visually distinct, and the model has clearly seen them during pre-training but isn't perfect at identifying them -- which makes the cases where it gets things wrong interesting. Throughout this post I'm using Qwen3.5-4B, a small open-source VLM. The post follows the order I did the investigation in: first looking at how well the model can name Pokémon from images, then extracting the model's internal Pokémon representations and visualising what they capture, then using those representations to ask questions about why the model makes the mistakes it does. It ends with a few demonstrations, including identifying which Pokémon my flatmate's cat, Logan, most resembles. These models aren't going away, and I think it's worth more people having a feel for what's happening inside them. As a result I've kept the main text beginner-friendly and pushed technical details into collapsible sections. If you're new to vectors or language models, there are explainers at the appropriate points.
Image Collection
There is a huge number of Pokémon images on the internet, I downloaded both a high resolution (HR) and low resolution (LR) set for the first ~500 Pokémon produced, which is approximately Gen1 to Gen4, I had a few of the starters from Gen5. An example of the LR and HR images:


I also downloaded a dataset of random images from Kaggle, there are images designed to be completely unrelated. I used these to create a control vector, see later.
Model Identification of Pokémon
I showed the model the image of each Pokémon and prompted with "What is the Pokémon in the image?".
I ran the model ten times at temperature = 0.7 (high enough to show uncertainty, low enough to keep coherent outputs). I later try to answer the question: "are wrong guesses near neighbours when the model is sampling under uncertainty". When temperature = 0.0, the model simply selects the most likely logit, which collapses all uncertainty and doesn't tell you anything about the model's range of possible predictions. I show some results below.
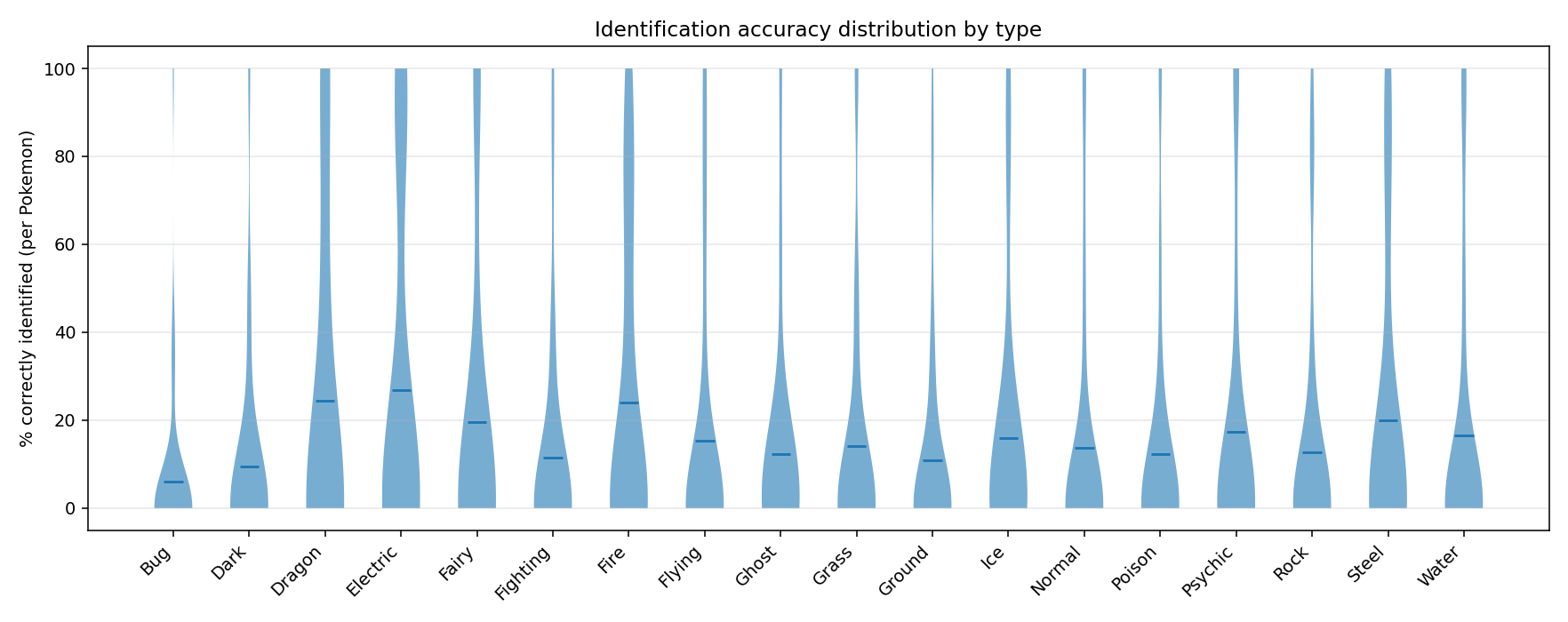
The figures above show the accuracy of the model in predicting the Pokémon correctly as a function of Pokémon type and generation.
When predicting Pokémon names from images specifically, the model identifies correctly ~20% of the time, with Dragon, Electric and Fire type Pokémon most correctly identified.
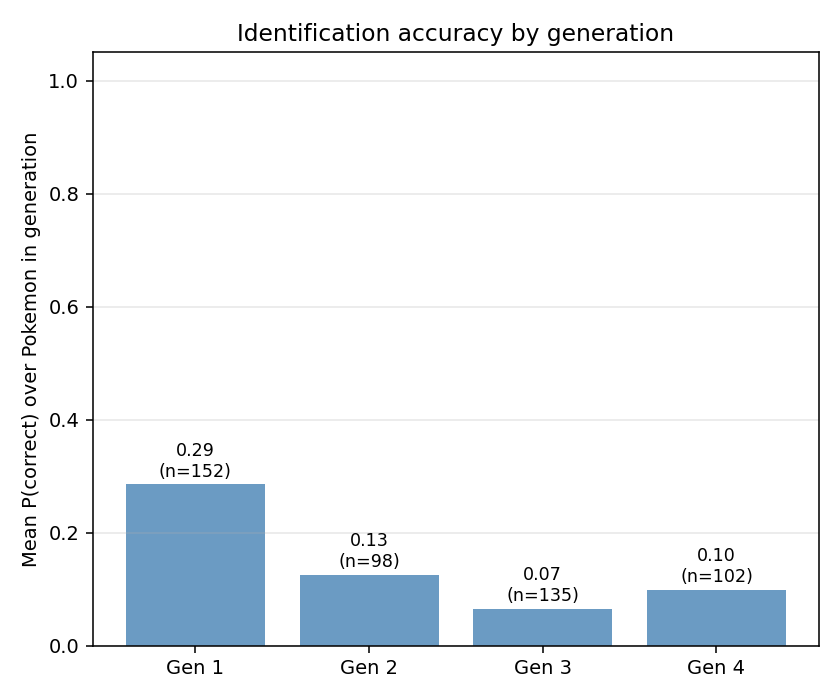
Generation 1 Pokémon are the most identifiable, whilst gen3 the least. Speculatively, gen1 has all the big hitters: Pikachu, Charizard, Gengar, Eevee. Pokémon that are more generally well known and more likely to be seen during pre-training than more obscure Pokémon.
The list of Pokémon correctly identified at least 90% of the time are shown below.
Leafeon, Lucario, Piplup, Turtwig, Latios, Gardevoir, Lugia, Teddiursa, Scizor, Umbreon, Marill, Mew, Mewtwo, Dragonite, Dratini, Articuno, Snorlax, Jolteon, Vaporeon, Eevee, Electabuzz, Onix, Gengar, Slowbro, Psyduck, Meowth, Jigglypuff, Raichu, Pikachu, Blastoise, Squirtle, Charizard, Charmander, Venusaur, Bulbasaur, Wailord, Pichu, Lapras, Arcanine
Pokémon that were identified 0% of the time (but the model did predict them for other Pokémon images) are shown below. The format is name: (number of times predicted, number of Pokémon predicted for)
click to show
Clefairy: (49, 26), Starmie: (46, 18), Ludicolo: (44, 19), Shedinja: (33, 22), Regigigas: (33, 11), Mime-jr: (32, 16), Crobat: (31, 17), Shuckle: (28, 21), Wailmer: (26, 18), Stantler: (26, 16), Mudkip: (25, 17), Slowpoke: (25, 12), Larvitar: (20, 15), Tangela: (20, 13), Wurmple: (20, 10), Sceptile: (20, 9), Poliwrath: (19, 16), Torkoal: (19, 13), Wigglytuff: (19, 12), Marowak: (19, 11), Camerupt: (18, 13), Drowzee: (18, 12), Grumpig: (18, 9), Staryu: (18, 9), Electivire: (18, 3), Surskit: (17, 13), Luvdisc: (17, 12), Golem: (17, 9), Gible: (16, 15), Parasect: (16, 6), Charmeleon: (16, 6), Porygon2: (15, 13), Machop: (15, 8), Kabuto: (15, 5), Bidoof: (14, 11), Munchlax: (14, 10), Dunsparce: (14, 10), Poochyena: (14, 9), Cranidos: (14, 6), Chansey: (13, 9), Koffing: (13, 9), Hitmonlee: (13, 6), Mankey: (13, 6), Golduck: (13, 2), Lunatone: (12, 7), Quagsire: (12, 6), Sneasel: (11, 10), Kricketot: (11, 3), Forretress: (10, 7), Kingdra: (10, 6), Mantyke: (9, 7), Registeel: (9, 5), Nidoqueen: (9, 5), Houndoom: (8, 8), Dewgong: (8, 7), Claydol: (8, 5), Vibrava: (8, 3), Donphan: (8, 3), Bonsly: (7, 6), Mareep: (7, 6), Snorunt: (7, 5), Furret: (7, 4), Nidoking: (7, 4), Taillow: (7, 3), Pineco: (7, 2), Chimecho: (6, 6), Aron: (6, 6), Rotom: (6, 5), Gulpin: (6, 5), Cresselia: (6, 4), Zigzagoon: (6, 4), Hippopotas: (6, 3), Seedot: (6, 3), Growlithe: (6, 3), Porygon-z: (5, 5), Happiny: (5, 5), Gligar: (5, 5), Buneary: (5, 4), Chingling: (5, 3), Mismagius: (5, 3), Mightyena: (5, 3), Hoppip: (5, 3), Pinsir: (5, 3), Kangaskhan: (5, 3), Voltorb: (5, 3), Groudon: (5, 2), Cradily: (5, 2), Spinda: (5, 2), Riolu: (4, 4), Lickitung: (4, 4), Honchkrow: (4, 3), Drifloon: (4, 3), Shinx: (4, 3), Salamence: (4, 3), Nosepass: (4, 3), Raikou: (4, 3), Ledyba: (4, 3), Ralts: (4, 2), Lotad: (4, 2), Cleffa: (4, 2), Uxie: (4, 1), Whiscash: (4, 1), Sandshrew: (4, 1), Drifblim: (3, 3), Starly: (3, 3), Zangoose: (3, 3), Skitty: (3, 3), Magby: (3, 3), Skarmory: (3, 3), Steelix: (3, 3), Flaaffy: (3, 3), Chinchou: (3, 3), Ledian: (3, 3), Shellder: (3, 3), Lopunny: (3, 2), Dusclops: (3, 2), Whismur: (3, 2), Swampert: (3, 2), Wooper: (3, 2), Goldeen: (3, 2), Probopass: (3, 1), Staraptor: (3, 1), Beldum: (3, 1), Tyranitar: (3, 1), Arbok: (3, 1), Lumineon: (2, 2), Drapion: (2, 2), Stunky: (2, 2), Combee: (2, 2), Wynaut: (2, 2), Lileep: (2, 2), Cacnea: (2, 2), Makuhita: (2, 2), Lombre: (2, 2), Politoed: (2, 2), Rhyhorn: (2, 2), Exeggcute: (2, 2), Tentacool: (2, 2), Gloom: (2, 2), Froslass: (2, 1), Snover: (2, 1), Carnivine: (2, 1), Rayquaza: (2, 1), Absol: (2, 1), Silcoon: (2, 1), Torchic: (2, 1), Suicune: (2, 1), Hoothoot: (2, 1), Rapidash: (2, 1), Gallade: (1, 1), Magnezone: (1, 1), Abomasnow: (1, 1), Croagunk: (1, 1), Bronzor: (1, 1), Purugly: (1, 1), Bibarel: (1, 1), Bagon: (1, 1), Spheal: (1, 1), Duskull: (1, 1), Feebas: (1, 1), Baltoy: (1, 1), Volbeat: (1, 1), Medicham: (1, 1), Slaking: (1, 1), Marshtomp: (1, 1), Snubbull: (1, 1), Murkrow: (1, 1), Ariados: (1, 1), Feraligatr: (1, 1), Aerodactyl: (1, 1), Kabutops: (1, 1), Porygon: (1, 1), Clefable: (1, 1), Butterfree: (1, 1), Wartortle: (1, 1)
There was approximately 5000 total predictions (~500 images x 10 predictions per image). As these Pokémon were predicted for other Pokémon but not themselves, the model has some memorisation of them as Pokémon, but is not able to identify from an image in ten attempts.
The model clearly has knowledge of Clefairy, Starmie, Ludicolo etc. as Pokémon, but was not able to correctly identify once. Is this a limitation in the model's understanding of the Pokémon's physical features? Or, does the model know how the Pokémon looks, but other names are more powerful during identification, presumably from pre-training asymmetry over certain Pokémon.
Asking model to describe the Pokémon Clefairy, I can assess if the model has a reasonable visualisation:
"Clefairy resembles a small, fluffy creature with a distinct **pink color scheme** ... A long, fluffy tail that often curls around its body ... with a prominent nose ..."

This description isn't bad, but Clefairy does not have a tail that curls around its body or a prominent nose. For Clefairy the model predictions were: 1 x Jigglypuff, 3 x Marowak, 3 x Cleffa, 3 x Wigglytuff. Jigglypuff, Cleffa, Wigglytuff all look really similar, and to be completely honest I wouldn't be able to identify with 100% accuracy today (though 11 year old me probably could).
Another Pokémon not self-identified was Ludicolo. The model's attempt to describe this Pokémon:
"Ludicolo is designed to look like a cheerful, anthropomorphic flower ... Its body is covered in green, leafy patterns that resemble a dress or a skirt made of foliage ... Its primary colors are bright green (leaves) and white (face and underbelly), giving it a fresh, summery appearance."

This description is also not great. Towards the end the model is straight up hallucinating features. I didn't rigorously test this, but generally the model's descriptions of Pokémon from the above list are not accurate (apparently Golduck is a "blue otter"; Sceptile is a "large agile tree"). When asked to describe Pokémon it could correctly identify over ~50% of the time, the descriptions were good (Gyarados is a large blue serpent; Psyduck is a plump duck with a prominent beak). However, the model being able to correctly describe the physical attributes of a Pokémon when asked does not mean it would produce that name when shown an image of that Pokémon. Conversely, the model might not describe a Pokémon accurately but be able to identify it. I am likely assessing two different model capabilities here; the model might not have a self-consistent latent space representation of every Pokémon.
From this short exploration, it seems the internal representation the model builds up from an image is pretty accurate. If it knows what a Pokémon looks like, it can identify it with high probability. If the model has a less good memory of certain Pokémon, it will produce other names when shown its image. It is the conversion from the latent representation to the correct Pokémon name, presumably in the later layers, is the limitation. The question then becomes: When shown an image of a Pokémon the model cannot recall, are the Pokémon that are guessed closer to this latent representation than other Pokémon the model has not guessed?
In order to test this I needed to extract Pokémon-specific vectors from the model's internal representation.
This requires hooking the model's activations when processing images of Pokémon, and storing them as vectors. I explain the methodology below.
Pokémon Vector Extraction
How I extracted the Pokémon vectors
I pass the images to Qwen3.5-4B. The model sees an input like so:
| Position | ID | Token | Text |
|---|---|---|---|
| 0 | 248045 | <|im_start|> | |
| 1 | 846 | 'user' | user |
| 2 | 198 | '\n' | |
| 3 | 248053 | <|vision_start|> | |
| 4 | - | [196 × <|image_pad|> tokens] | |
| 200 | 248054 | <|vision_end|> | |
| 201 | 3710 | 'What' | What |
| 202 | 369 | ' is' | is |
| 203 | 303 | ' in' | in |
| 204 | 411 | ' this' | this |
| 205 | 2099 | ' image' | image |
| 206 | 30 | '?' | ? |
Where <|vision_start|> is a text token that is telling the model there are image tokens upcoming, these are denoted by the text token <|image_pad|> in Qwen3.5. You can see there are 196 of these vectors. Each vector has hidden size dimension and represents a single patch in the input image. A patch is a square section of the image, and in this case is made up of 16x16 pixels and therefore has 16^2 total pixels. Each pixel has 3 values associated with it (think RGB). The model flattens each patch into a 3 x (16^2) vector, it passes through a linear projection to have the dimension required for the vision model, which is 1024 here. Qwen3.5-4B uses rotary positional embedding: each patch's query and key vectors are rotated based on the patch X and Y coordinate. The vision model then computes global attention (no mask) over all other patches and updates the hidden dimension at each of the 24 layers in the vision encoder. Finally, the model passes the patch vectors through a final linear projection to match the language model's hidden dimension, 2560.
So when you see the <|image_pad|> placeholder, it has already been processed by the vision encoder section of the model, it is now written into the residual stream of the language model. Intuitively, I think of each patch token/vector as holding information about the patch in the context of the entire image. A patch vector might have information related to "a dogs ear in an image of a dog in the park", or something. This information has been written by the vision encoder to be accessible by attention during the language model forward pass.
I extract the residual stream vector on all <|image_pad|> tokens, and take the mean over them. I compute this mean vector at all transformer layers (32). I do this for ~500 Pokémon images, and ~500 control images. I average the per layer vectors over the entire set of control images to try and capture any "this is an image" signal, or signals relating to an image, but not Pokémon related.
I then construct my Pokémon vectors by subtracting the control vector at each layer off the Pokémon vector at that layer. These are henceforth the "raw" vectors. I also compute a standardised version of the raw vector, which is the z-score. This vector normalises each dimension in a vector by subtracting the mean over all Pokémon vector dimension values, and divide by the standard deviation.
Z-Score Normalization (Per Dimension)
For a dataset of N=500 vectors, each with D=2560 dimensions, I normalize each dimension j independently:
Variables per dimension j:
- • xi,j: The value of the j-th dimension in the i-th Pokémon vector.
- • μj: The mean of dimension j across all 500 vectors.
- • σj: The standard deviation of dimension j across all 500 vectors.
The standardised vector is not often calculated for concept vectors. In this case, I found that certain dimensions in the extracted vectors grow quickly in deeper layers. These dimensions may encode literal "this is a Pokémon" signals, and sometimes swamped any between-Pokémon differences. To account for this, I computed the z-score to reduce this swamping effect.
Note I use a single HR and single LR image per Pokémon, so the per-Pokémon vector is built from two depictions only. The HR/LR consistency I introduce below partially tests this: if the two vectors agree, the signal is probably about the Pokémon rather than the specific image idiosyncrasies; ideally I would use many different images per Pokémon.
I computed Pokémon-specific vectors for the HR and LR datasets individually and also computed the average between these two. To find the layer at which Pokémon individuality is most strong, I produced a metric that finds which layer different Pokémon are most distinct. At each layer the metric computes both the within and between terms. The within is the cosine similarity between the HR and LR vectors for a Pokémon. Whilst the between term computes the cosine similarity between all pairs of Pokémon for both the HR and LR datasets. The maximum positive difference between these terms, gap = within - between, represents the layer at which the HR/LR vectors for the same Pokémon are most similar whilst the vectors between different Pokémon are most separate. The idea being where this value peaks represents where the model most strongly separates different Pokémon visually.
I found that the value actually peaked at the final layer for the raw vectors. I decided this was due to the increase in absolute value of the vectors towards the final layers. This means the cosine numerator was driven upwards as certain dimensions swamped the cosine similarity. This is the reason to also calculate the standardised vectors, which peaked at layers 24-26.
Importantly, the cosine ratio jumped substantially from layers 18 -> 19. Layer 19 is a full attention layer (as opposed to linear attention layers), and clearly the penny drops during information routing here, up to a maximum at layer 24.
I now have a set of Pokémon-specific vectors, both in raw (control subtracted) units and standardised (z-score of raw vectors).
Introduction to Vectors
I am new to vectors
A vector is a list of numbers. A = [2, 4, 3] is a vector of three elements or dimensions. B = [-1, 5, 4, 2] is also a vector -- it has one additional dimension relative to A -- but it is still just a list of numbers. I denote them A and B here, but I can call them anything. For example, Pikachu = [1, 4, 8, -2, ...] is a vector. In a real world situation, your physical position in the room you are in could be defined by a vector of three dimensions. Position_in_room = [x, y, z]. A vector is always defined relative to some point, often a vector of zeros: [0, 0, 0, ...], called the origin. In the position example, you are free to choose your origin point, maybe you choose the point where the door is. Every position in the room is then defined by a vector relative to this origin.
For now, let's move the origin to be where you are right now: your position is now the origin. Objects in the room with you have their own vectors representing their position relative to you. Objects close together will have similar vectors. For example, your curtains might be physically close to your window. Visualising an arrow from you to those objects will produce two arrows that are highly aligned. There is a mathematical method to compare the similarity of two vectors, called the cosine similarity. But for the remainder of this blog -- or until you get bored -- think of the similarity as how aligned these vectors are. The more similar, the more aligned.
In this example, I have introduced vectors as describing a physical location. But vectors can describe many different things. A common example is velocity. Objects have velocity in three directions. As I hinted to before, a vector can have a lot more dimensions than three, but I find it tricky to visualise a vector in more than three dimensions. In principle they are no different, the way I mathematically find the cosine similarity is the same whether the vectors are 4D or 15627D.
The vectors I introduce in the next section don't define physical position or velocity, they attempt to define "Pokémon-specificness". Each Pokémon will be represented as a vector with 2560 dimensions! Every particular dimension in this vector might represent some Pokémon related topic. For example, the first dimension might represent how "mouse-like" the Pokémon is. Pikachu would have a large number value for this dimension! I therefore expect similar Pokémon vectors to point in similar directions in this 2560 dimensional space, just like your curtain and window position vectors point in similar directions.
Language Modelling
A language model (like ChatGPT) functions by iterating over a sequence of text (e.g. "the cat sat on the") N times, where N is the number of layers in the language model. I am using Qwen3.5-4B here. The 4B means 4 Billion model parameters, this is really small relative to the best models today. Qwen3.5-4B has 32 layers. For the possible sequence:
"The cat sat on the"
The model first produces a vector (remember, a list of numbers) for each word in the sequence. So the word "cat" in the above sequence has it's own vector, representing the model's understanding of "cat". After every layer, each vector becomes more and more enriched with context, by learning from words causally before them. The vector for "cat" is updated 32 times before the model finally produces the next word, maybe "mat" or "chair" in this case. The important thing is that after every layer, the vectors associated with each word have learnt a bit more. Maybe in the 10th layer, the vector for "sat" understands it is a verb describing the action of a cat.
I can similarly treat each Pokémon as its own vector. This vector changes slightly after every layer, learning new information each time. I find that layer 24 happens to be the layer where the Pokémon vector most strongly understands the semantic nature of the Pokémon. There are still 8 more layers after this, so why doesn't it become even more enriched in those later layers is a story for another day.
The Pokémon vector I obtain for each Pokémon is extracted by showing the Vision-Language model an image of the Pokémon, and recording the vector activations the model produces when processing the image. As I record the vectors at every layer, I have 32 extracted vectors per Pokémon.
Visualisations of Pokémon Vectors
At this point I have extracted a vector for every Pokémon in our dataset, (I have a "Pikachu" vector, a "Bulbasaur" vector, etc.) and each vector encodes the Pokémon semantically. Recall the vector for every Pokémon is updated every layer (32) but is always a list of 2560 numbers.
As each vector is representing each Pokémon, I expect that similar Pokémon have similar vectors. The way I can compare the similarity between two vectors is using the cosine similarity. For these Pokémon vectors, the similarity represents "how similar are these Pokémon semantically". A value of +1.0 is an identical match, and -1.0 is opposite.
Equipped with the cosine similarity measure, let's compute it for two hand picked example Pokémon: Seel and Pidgey. The vectors compared in the following are the vectors from layer 24 of the model, so they've been updated 24 out of 32 times at this point!
Similarity Analysis: Seel


1. Dewgong (+0.922)

2. Sealeo (+0.908)

492. Starmie (+0.569)
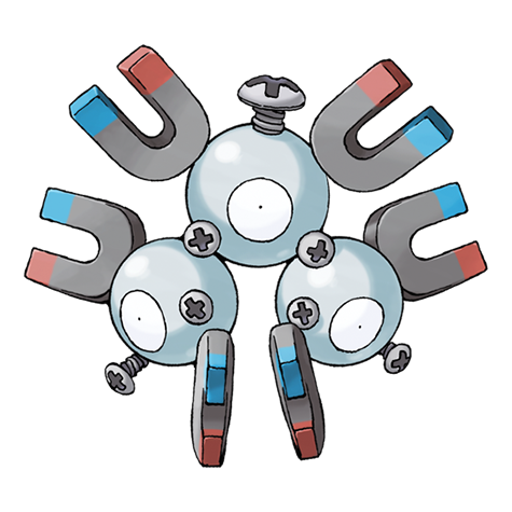
493. Magneton (+0.562)
Similarity Analysis: Pidgey


1. Spearow (+0.958)

2. Pidgeotto (+0.957)
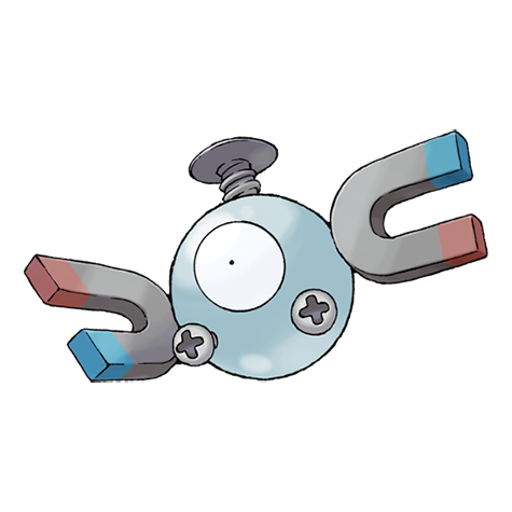
492. Magnemite (+0.516)
493. Magneton (+0.480)
I see that whilst the most similar Pokémon are very close (+0.958), the least close Pokémon still have cosine similarity of around +0.5. Note the same Pokémon (Magneton) appear as least similar to both Seel and Pidgey, despite Seel and Pidgey themselves being very different. This tells us the space is structured with a coherent global geometry where geometric/mechanical Pokémon sit far away from organic ones. You might think a similarity of +0.5 is quite similar, if opposite is -1.0. But remember these vectors are representing Pokémon, and of the entire space of images a model can process, Pokémon is a very very small subset -- I should expect them to be similar. After all, even very different Pokémon are cartoon looking animal/robot like monsters; they are not photo-realistic, they are not landscapes, architectural, or cars. Later on, I change the Pokémon vectors to capture the differences between only other Pokémon vectors. Using these "standardised" vectors, it makes more sense to expect similarity values between -1.0 and +1.0.
Principal Component Analysis of Pokémon Vectors
I won't go into detail about Principal Component Analysis (PCA) here. Briefly, it is a tool used to reduce a high dimensional set (e.g. our Pokémon vectors of 2560 dimensions) to a lower dimensional set, whilst still capturing the most important information. In the following I reduce the vectors of 2560 numbers down to a vector of only two numbers by capturing the most important information.
The figure below shows the first two principal components for our Pokémon vectors. As each vector is now only two numbers, I can plot them on a 2D scatter plot (not something you can do with 2560 numbers!)
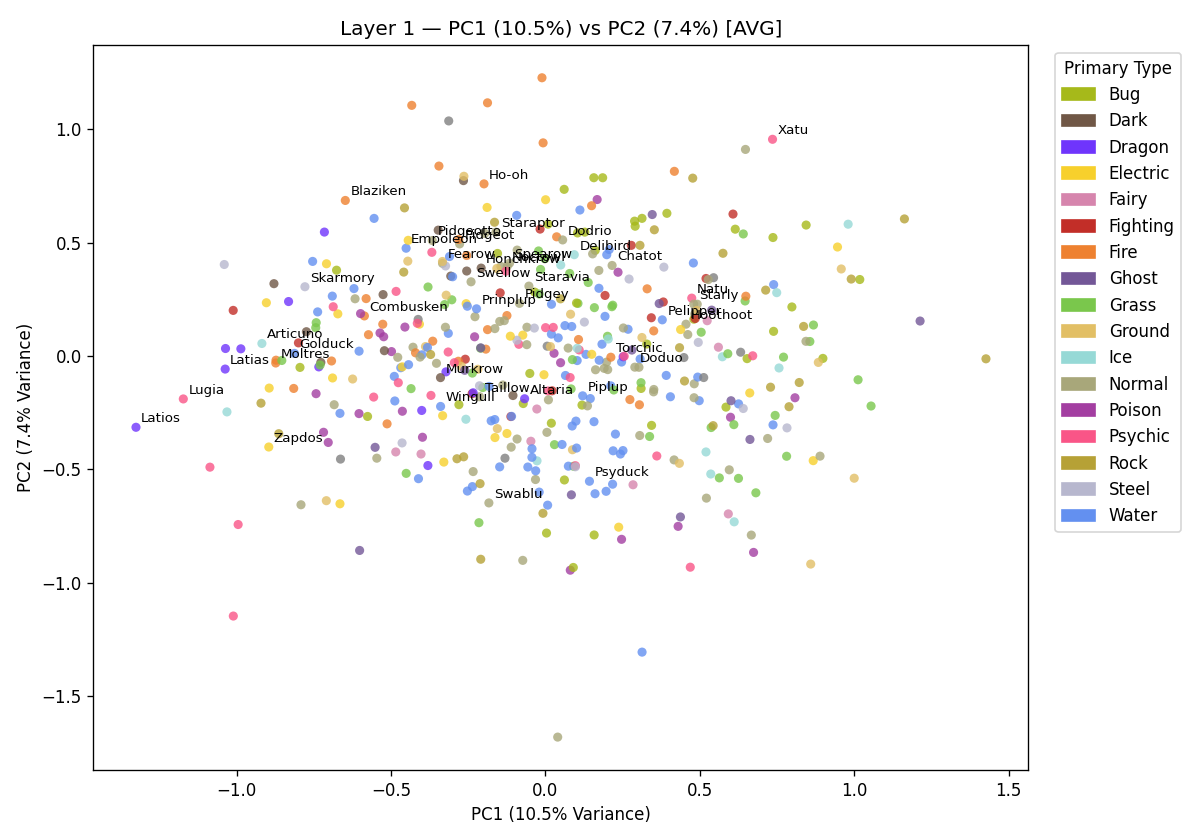
Each point is a Pokémon vector thats been reduced to a position in 2D. I show the names of some of the Pokémon. If you are not an expert, all the Pokémon labeled are birds. I might expect Pokémon that are birds to be semantically similar, so why aren't they more clustered together? Well, the figure shows the Pokémon vectors after layer 1 of the model! The vectors have only been updated once, the model has not had time to extract the important features that cluster similar Pokémon together yet. We are far away from layer 24 where the vectors most strongly represent semantically distinct Pokémon!
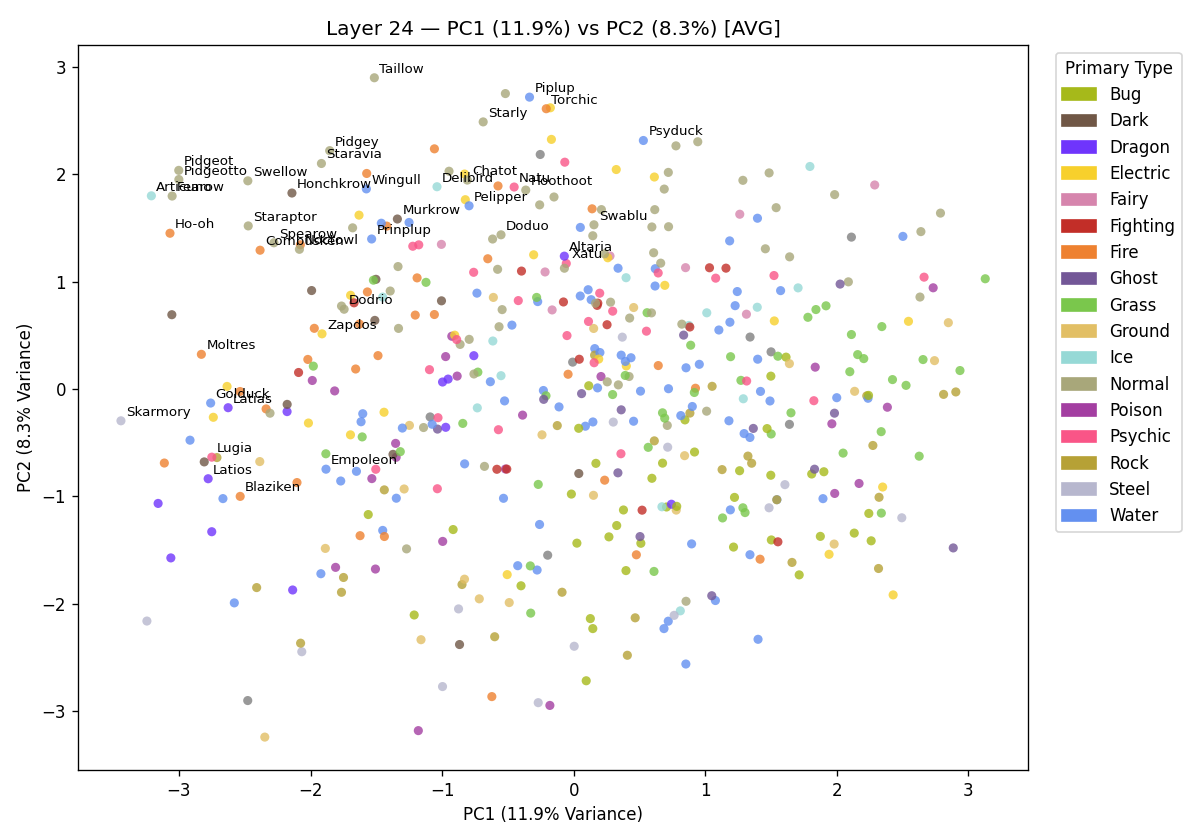
This is a bit better, the bird Pokémon vectors at layer 24 are now much more tightly clustered. This result also shows that reducing the vectors of size 2560 down to two has still managed to capture real visual distinctions between Pokémon vectors. The model really has represented bird Pokémon differently to other Pokémon. These two dimensions only show about ~17% of the total variance. This means 83% of the total information is not being displayed (you lose information going from 2560D to 2D). However, the model still represents birds as strongly distinct in the vector space. By reducing to only two dimensions, bird like distinctions are recovered. If I instead label serpentine Pokémon:
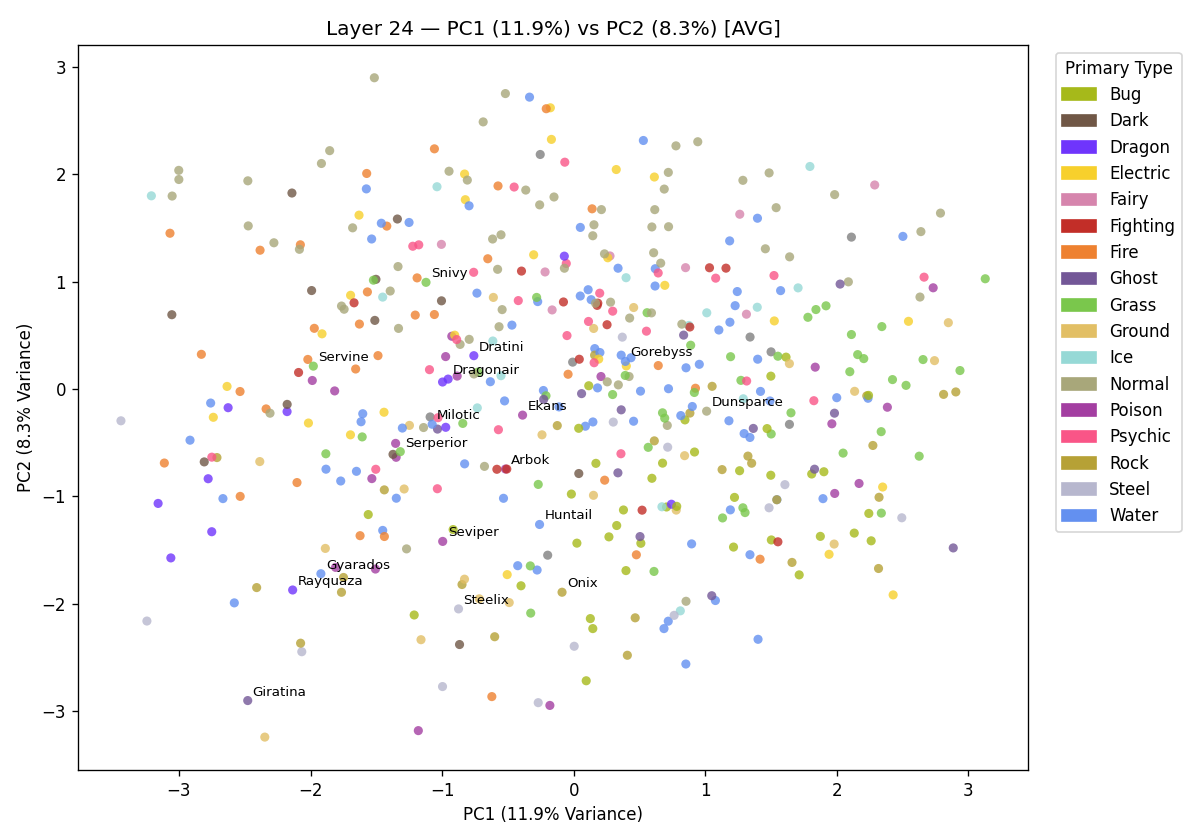
There is no real evidence of clustering here. These Pokémon vectors will likely have larger cosine similarity but when reducing to only two dimensions and chucking away 83% of the variance, the serpentine distinction has not survived.
A natural question: when the model attempts to identify a Pokémon image and gets it wrong, does the guessed Pokémon vector have a higher similarity to the target Pokémon vector than randomly selecting Pokémon vectors?
Are Model Guesses Closer to Similar Pokémon?
To explore this question I had to go back and look at what the model predicted for each Pokémon image. During model prediction, Clefairy was the most guessed Pokémon that itself had 0 correct self-identifications (0/10 identifications on Clefairy image, but predicted Clefairy for multiple other images).
Recall for Clefairy the responses were: 1 x Jigglypuff, 3 x Marowak, 3 x Cleffa, 3 x Wigglytuff. When looking at the standardised Pokémon vectors at layer 24, the similarity scores with the Clefairy vector are shown below.
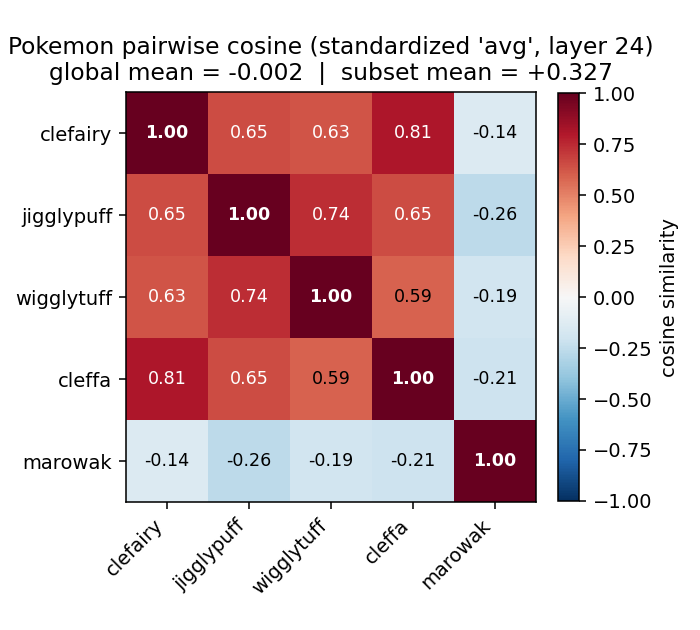
The heatmap shows that all Pokémon vectors are highly aligned, with the exception of Marowak, which has a similarity less than the mean similarity over all Pokémon. The global mean is ~0 (recall the standardised vectors have per-direction mean of 0). Clearly the model has a good internal representation of the Clefairy image, but was unable to predict the name even though it predicts Clefairy for other Pokémon (e.g. 2 x when identifying Cleffa).
This suggested the model is trying to identify these Pokémon, and producing names that are actually more similar than chance would predict.
Confusion Rank
The Confusion Rank (CR) is a metric used to determine how incorrect the model identification is when shown an image of a target Pokémon. Concretely, the rank is defined as follows.
Recall the model attempted to identify each Pokémon ten times. For 493 Pokémon this is approximately 5000 total predictions. For each target Pokémon, I have the ten Pokémon names the model guessed for the target Pokémon. I can produce a pair of (target, guess) predictions, for example (Seel, Dewgong). There are ~5000 of these predictions. For each pair, I compute the similarity between each Pokémon -- recall the similarity between Seel and Dewgong was over +0.922 using the non-standardised Pokémon vectors. If I take entire set of 5000 pairs, and compute the mean similarity over all predictions, I get some idea of how similar the guessed Pokémon is to the target Pokémon on average. In reality, the similarity score is slightly Pokémon-specific -- some Pokémon are just more "normal" and have more similar Pokémon, so are more likely to have higher similarities on average than less conventional looking Pokémon. Not all Pokémon have a closest similarity of +0.922, some might have the closest Pokémon as similarity of +0.8. To account for this I instead define the rank. Which is the number representing how close the guessed Pokémon is to the target Pokémon out of the entire set of 493, as defined by the similarity. For the (Seel, Dewgong) example, the rank is 2 (as in 2/493), Dewgong is the most similar to Seel out of all Pokémon that are not Seel itself. The CR is then the median of all ranks for all pairs in the ~5000 pairs. I excluded correctly-guessed pairs from this calculation, since the hypothesis concerns only confusions.
Next, I randomly swap the target Pokémon in the (target, guess) pairs by permuting the target Pokémon for all pairs. After this, I remove all cases where the new (target, guess) is correct (e.g. I ignore all cases where I get (Pokémon_a, Pokémon_a)) and finally recalculate the median rank in this case. By doing this I am effectively asking the question: "given exactly the targets I saw and exactly the guesses I saw, is the pairing between them better than chance pairing?"
Under the frequency-corrected permutation null -- where the model's overall guessing tendencies are preserved but each guess is randomly reassigned across targets -- the median confusion rank is around 243, near the chance value of (493−1)/2 ~ 246. The observed median was 60 in the standardised space and 74 in the non-standardised space. Across 2000 permutations, no shuffle produced a median this low (p < 0.0005). Meaning: even after controlling for the model's biased guess distribution, the wrong names sit far closer in Pokémon vector space to their targets than chance would predict.
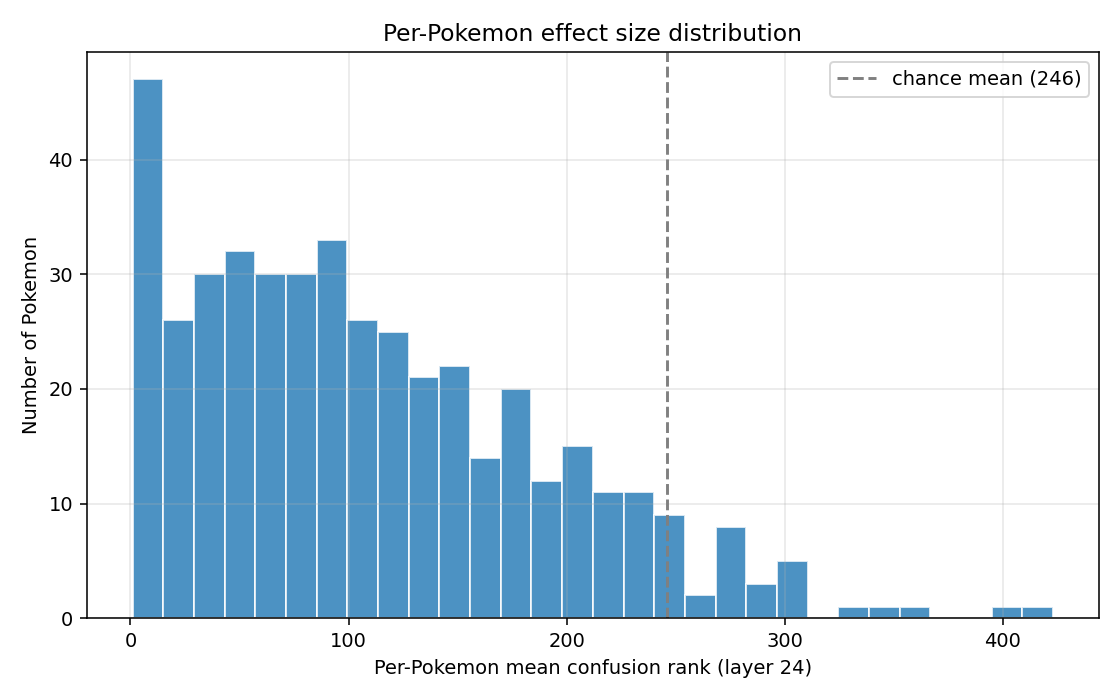
For each Pokémon, I determined the mean of all 2000 confusion ranks. The figure above shows the histogram of per-Pokémon mean confusion rank at layer 24. The vast majority of Pokémon have mean confusion ranks way less than the chance mean.
Injecting Pokémon Vectors
Just as I extracted Pokémon vectors from the model activations, I can add them back in to model layers during inference. Injecting concept vectors can steer the model towards outputs related to the injected concept. I start by steering with the non-standardised Pokémon vector on all user tokens at layer 24 with the prompt "Describe the creature in this sentence". Recall the Pokémon vector was extracted when the model processes an image of the Pokémon. As I am injecting at layer 24, the model does not have any external influence until it has already passed over the sequence -- "Describe the creature in this sentence" -- 23 times. I show a few examples below.
Seel: "cute, fluffy creature with big eyes and a wagging tail"
Ludicolo: "Leaf-like patterns decorate the surface. The creature is camouflaged in the trees. Its body is covered with green scales. This makes it look like a living fern. It moves slowly through the forest..."

Salamence: "draconic; hissing; scales; massive; serpentine"
Dewgong: "Pokémon! Are you referring to a specific one? I'd love to help describe it! Just tell me its name. 😊🔥⚡🌊🌿🐉"

Mewtwo: "prehensile tail and webbed feet. **Correction:** The sentence you provided ("prehensile tail and webbed feet")"
These examples are cherry-picked, but they show that the model is reading Pokémon-specific signals from the injected vectors. As I inject the raw non-standardised vector, many responses mention Pokémon in some way, as can be seen from the Dewgong entry. The Mewtwo entry is interesting, the sentence "prehensile tail and webbed feet" was never physically in the prompt, these are semantic level concepts pulled from the injected vector.
Pokémon vectors therefore carry some semantic information about the underlying Pokémon. Demonstrating causality with injection is another good result as it demonstrates these vectors actually meaningfully alter the model's computation, in addition to having the neat, self-consistent structure I saw previously.
Think of a Pokémon
To further test how well the Pokémon vectors capture Pokémon-specific semantics, I steered whilst using the prompt "Visualise any Pokémon. Just tell me the name." This prompt will elicit a baseline response without steering. Does steering with specific Pokémon vectors move this baseline towards Pokémon with higher similarity to the injected Pokémon?
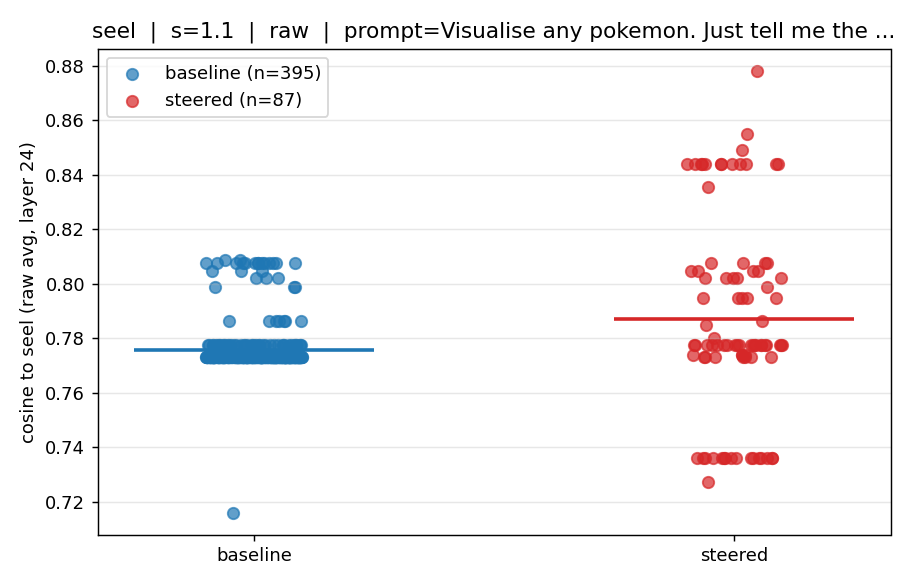
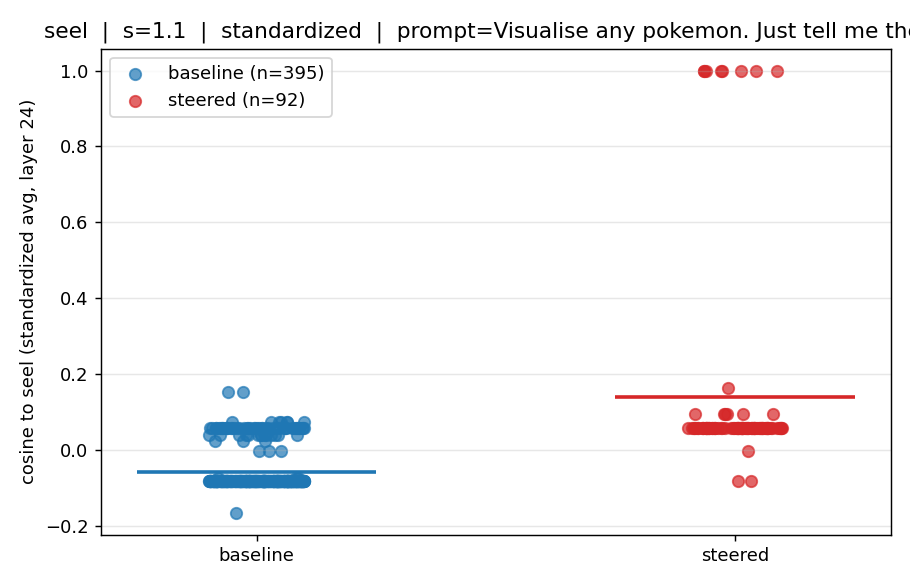
It turns out yes. When I inject with both the raw and standardised Pokémon vectors, we see an increase in the mean similarity (horizontal line) between injected Pokémon vector and vector of the Pokémon the model outputs. When injecting the raw vector, the model outputs a larger range of Pokémon names -- this is not surprising, the steering vector captures a huge "Pokémon" signal, the Seel signature is not as cleanly separated by the model. Injecting with the standardised vector we also see an increase in mean similarity between injected Pokémon vector and model output Pokémon vector. Most interestingly, the model never output "Seel" when injected with the raw vector. When injected the standardised vector, "Seel" is predicted ~10% of the time. The standardised vector is much more efficient at navigating the model output within the Pokémon sub-space.
Does this standardised vector capture creature related differences? I injected the raw and standardised vectors into the model with the prompt "Visualise any animal. Just tell me the name."
For the baseline, the model selects pretty classic animals: "Elephant", "Eagle", "Cheetah", etc. When injecting the raw "Seel" vector, I get outputs like "Pokémon", "Pikachu", "Seal", "cute". But for the standardized vector, the output is almost 100% "Seal". The standardised vector has captured animal related semantic differences very cleanly.
When exploring this section I happened on an interesting result. When injecting "Dragonite", I found the mean similarity actually dropped relative to the baseline. When looking into this I found that the baseline absolutely loves thinking of "Charizard", who happens to be the nearest neighbour of Dragonite. When I injected Dragonite, I found the model would sometimes output Dragonite, but due to the steering, moves away from its baseline distribution. The number of Charizards dropped drastically, whilst Dragonite increased slightly. This caused the mean similarity between the model output Pokémon and Dragonite to drop. This exposes a limitation of mean cosine as a measurement, as it is a function of the baseline. Had I instead asked the model to think of a small Pokémon (and the baseline thereby moved off Charizard), the cosine would have increased with steering. Counting Dragonite-specific outputs would also work as an alternative metric.


Playing around, it seems the raw vector also capture Pokémon-specific signals and knowledge, whilst the standardised vector captures physical level attributes. When I inject with the raw Seviper (left) vector, the model often output a "poisonous" frog; not a snake. Seviper is a poison Pokémon, but it's not all that defining from the image alone. The standardised vector produced "snake" over 50% of the time. When injecting the Grumpig (right) raw vector, the output was steered towards prehistoric animals from the past. When steering with the standardised vector the model produced "pig" overwhelmingly.
Identifying Non-Pokémon with Similarity Scores
Switched on readers might have thought of another use case of the extracted Pokémon vectors. When I show the model an image, the same computation occurs when the model attends over the image tokens, building up a representation of the image. Can I extract the image vector, just as I did for the Pokémon vectors and see which Pokémon vectors have the highest similarity?
This is essentially asking: which Pokémon does this image most resemble? I extract the mean layer 24 vector from the image tokens during a model forward pass for a series of images. For a bit of fun, I hide the closest neighbours so you can have a guess first!
Using an open-sourced fine-tuned diffusion model as a Pokémon Generator, I created some fakemon for this section. I show results when using both raw and standardised vectors when selecting nearest neighbours. You will see the raw vectors have similarity 0.8-0.9 whilst standardised are in the range 0.4-0.5. These values are similar to what we have encounted when comparing real Pokémon vectors. This is not surprising given I am using fake Pokémon which contain a strong 'Pokémonness' signal. The standardised vectors are a more meaningful comparison for identifying which specific Pokémon the image resembles.

Answers

1. Purugly (+0.876)

2. Glameow (+0.873)

3. Delcatty (+0.872)

4. Espeon (+0.871)

Answers

1. Gyarados (+0.889)

2. Rayquaza (+0.879)
3. Seviper (+0.872)

4. Dialga (+0.866)

Answers

1. Leafeon (+0.584)

2. Mightyena (+0.539)

3. Shiftry (+0.533)

4. Arcanine (+0.530)

Answers

1. Aggron (+0.545)
2. Purugly (+0.422)

3. Kabutops (+0.411)

4. Glalie (+0.410)
Photo-Realistic Examples
Does this still work when using photo-realistic images? Well, the similarity values will not be as high, but the rankings are what we care most about.

Answers (Standardised)

1. Houndour (+0.555)

2. Poochyena (+0.389)
3. Arcanine (+0.345)

4. Vulpix (+0.341)

Answers (Standardised)

1. Persian (+0.447)
2. Glameow (+0.373)

3. Meowth (+0.346)
4. Purugly (+0.326)

Answers (Standardised)

1. Sudowoodo (+0.356)

2. Bonsly (+0.336)

3. Torterra (+0.321)

4. Shaymin-land (+0.292)
When using raw vectors, the absolute similarities are in the range 0.3-0.4. This is less similar than even the least similar Pokémon pair. When raw vectors are used the results are largely similar, though Torterra is actually the number 1 most similar.
Logan
And finally, my favourite part of this entire post: Which Pokémon is Logan the most similar to? I have many many images of Logan so I use a few and collate the results.

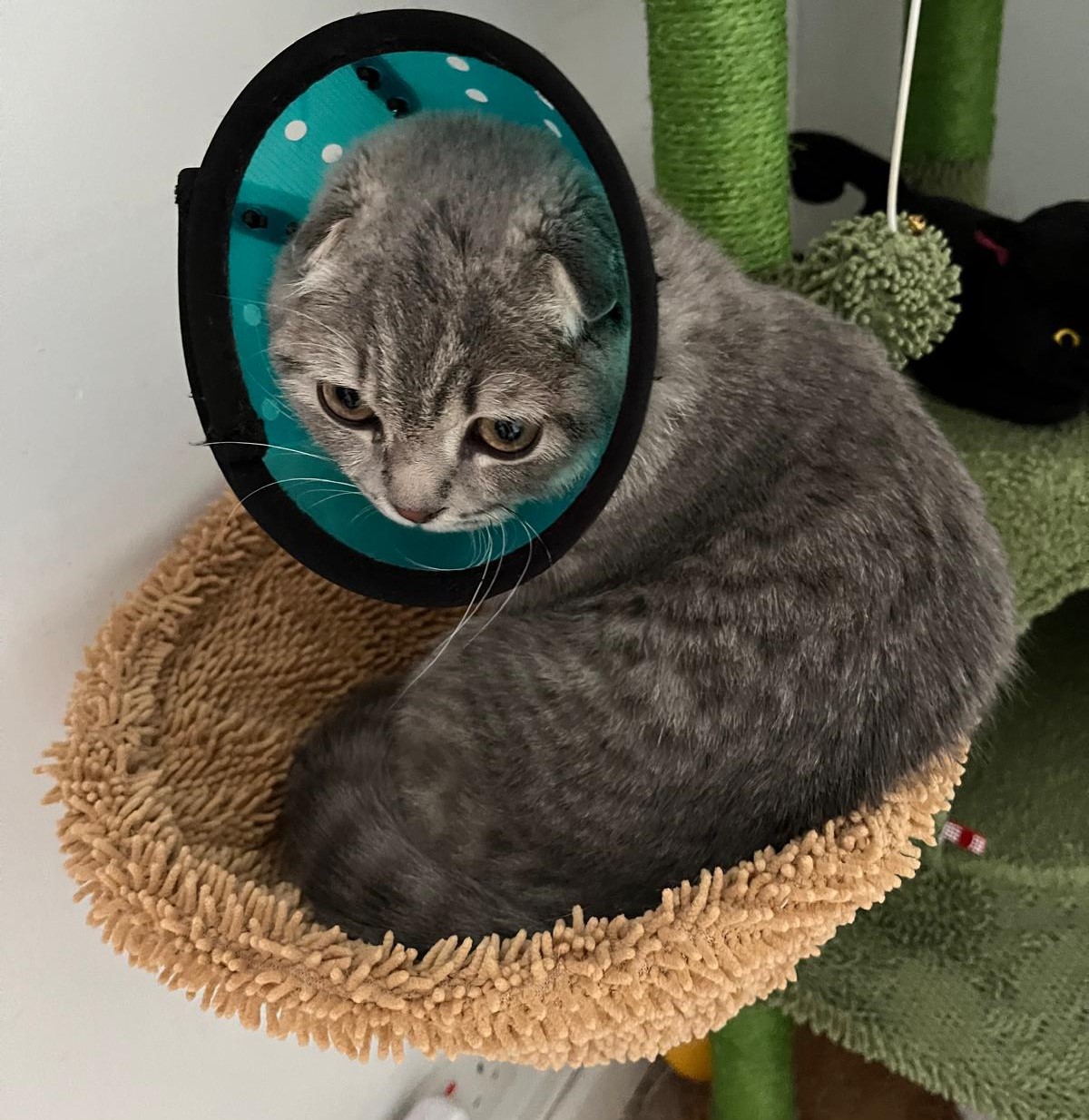


Answers (Standardised)

1. Slakoth

2. Swinub
3. Glameow
4. Meowth
The model deffo saw Logan's lack of ears and thought yeh you know what you're definitely a Swinub.
Future Work
I aim to track the circuitry that unfolds when the model processes an image, to producing the correct Pokémon name. Using various mech interp techniques will help shed light on what goes on internally during this particular task. Initial results are pretty interesting! I hope to post this follow up soon.
Appendix
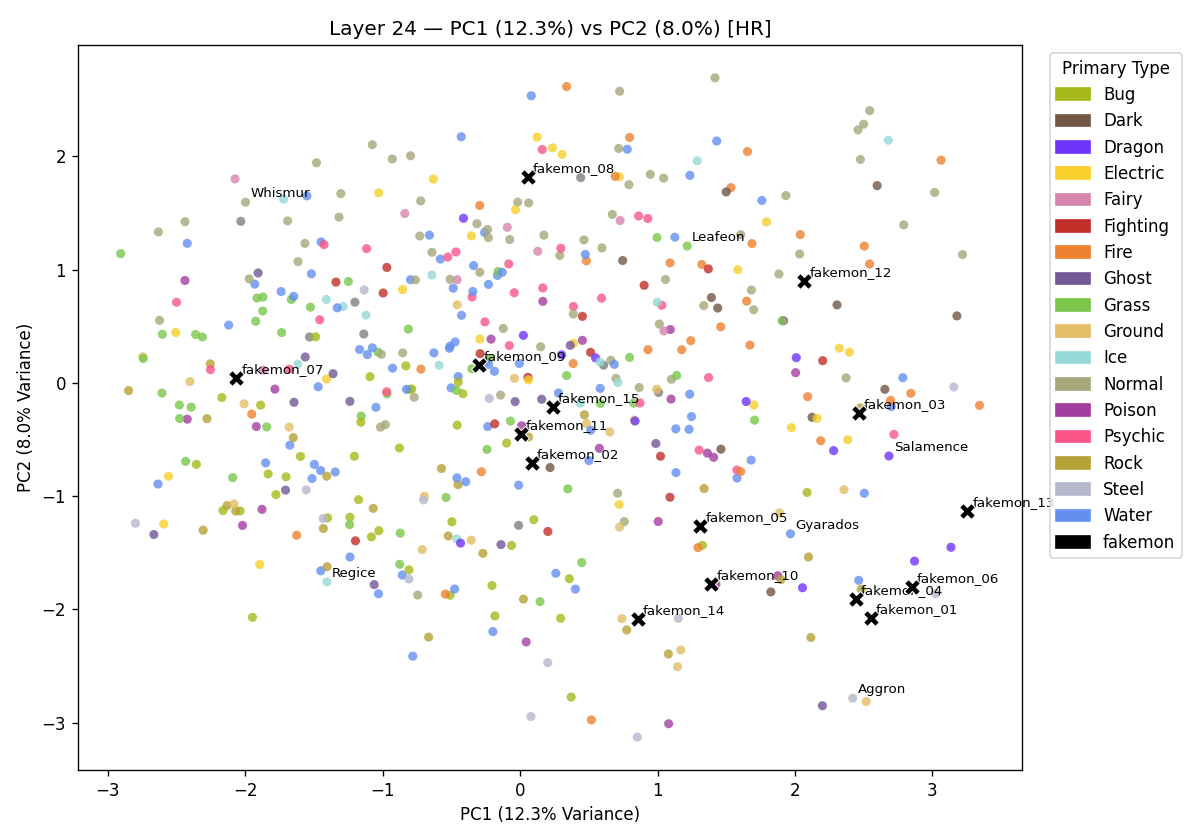
The model represented the fakemon in a very similar space to real Pokémon.
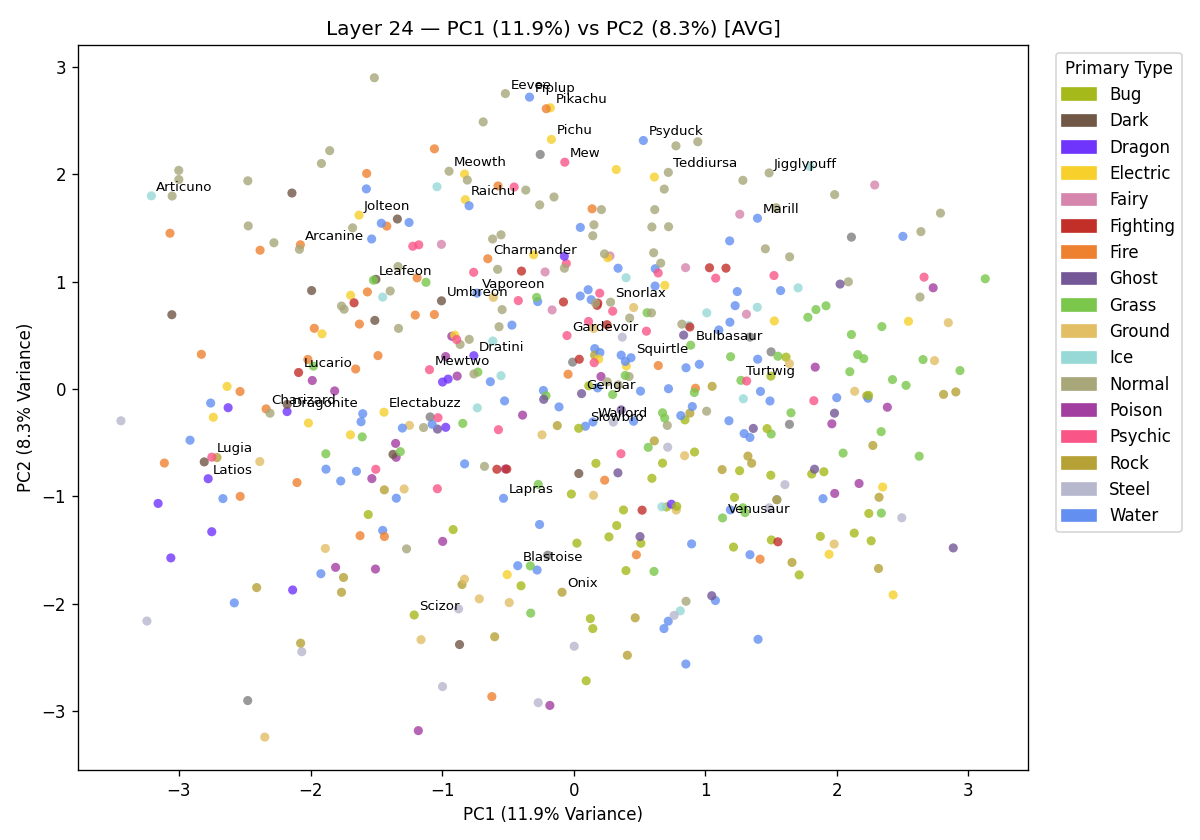
The model does not cluster Pokémon it correctly identified 90% of the time.
AI Assistance
A big thanks to Claude Opus 4.7 and Gemini-3-Fast for this project. Opus wrote all of the code for this project, and suggested the method used for testing the null hypothesis. Gemini-3-Fast helped with html formatting.
Disclaimer
Legal Disclaimer: This blog post is for educational and research purposes only. Pokémon and all associated character names, imagery, and trademarks are the sole property of Nintendo, Creatures Inc., and GAME FREAK inc. This project is entirely non-commercial and is not affiliated with, endorsed, or sponsored by The Pokémon Company or Nintendo.
Technical Note: The analysis featured in this post was generated using Vision-Language Models (VLMs). All model interpretations, classifications, or descriptions of imagery are the outputs of artificial intelligence algorithms and may contain errors or algorithmic hallucinations.